利用NVIDIA Isaac Transport for ROS提升自定义ROS图形性能
NVIDIA Isaac Transport for ROS(NITROS)是随 ROS 2 Humble 加入的两项硬件加速功能——类型适配和类型协商。
类型适配使 ROS 节点能够使用针对特定硬件加速器优化的数据格式进行工作。经过适配的类型用于处理图形,以消除 CPU 和内存加速器之间的内存拷贝。
通过类型协商,处理图中的不同 ROS 节点可以公布其支持的类型,ROS 框架也可以选择数据格式,从而实现理想的性能。
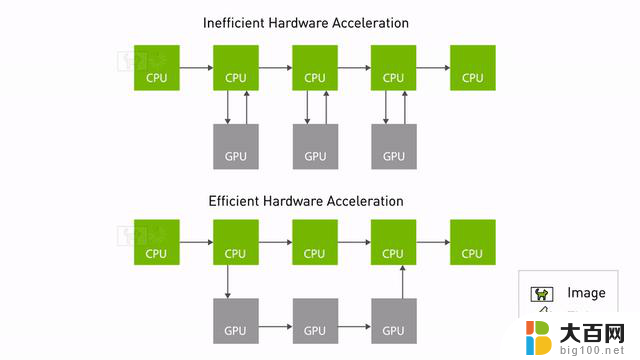
图 1. NITROS 通过减少 CPU 和 GPU 之间的内存拷贝,实现高效加速
当两个支持 NITROS 的 ROS 节点在图中相邻时,它们可以通过类型协商发现对方,然后使用类型适配共享数据。通过消除不必要的内存拷贝,类型适配和类型协商可共同显著提高基于 ROS 的应用中的 AI 和计算机视觉任务性能。
这不仅减少了 CPU 开销,还优化了底层硬件的性能。图 1 显示了使用 NITROS 的高效硬件加速。数据可以从 GPU 内存中访问,而不需要频繁地复制 CPU。
由于 ROS 框架与不支持协商的传统节点保持兼容,因此可在处理图中结合使用基于 NITROS 的 Isaac ROS 节点和其他 ROS 节点。支持 NITROS 的节点在与非 NITROS 节点通信时,其功能与典型的 ROS 2 节点相同。大多数 Isaac ROS GEM 都是通过 NITROS 加速的。
请通过 NVIDIA NITROS 文档进一步了解关于 NITROS 和系统假设的更多信息: https://nvidia-isaac-ros.github.io/concepts/nitros/index.html
搭载 NITROS 的 NVIDIA CUDA
NVIDIA CUDA 是一种并行计算编程模型,可大幅提高搭载 GPU 的机器人系统的运行速度。自定义 ROS 2 节点可通过代管式 NITROS 发布器和代管式 NITROS 订阅器,使用搭载 NITROS 的 CUDA。
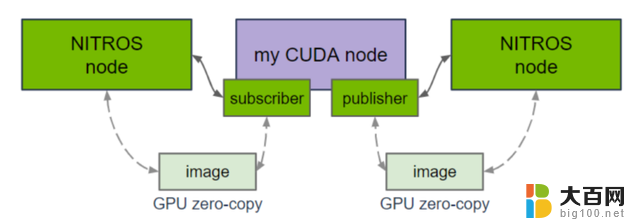
图 2. 搭载 NITROS 的 CUDA 概览
ROS 节点中的 CUDA 代码可以使用代管式 NITROS 发布器,并与支持 NITROS 的 Isaac ROS 节点共享 GPU 内存中的输出缓冲区。这样就省去了昂贵的 CPU 内存拷贝步骤,从而提高了性能。NITROS 还能通过发布与普通 ROS 2 消息相同的数据,来保持与非 NITROS 节点的兼容性。

图 3. ROS 2 节点中的 NITROS 发布器
在订阅器方面,ROS 节点中的 CUDA 代码可以使用代管式 NITROS 订阅器来接收 GPU 内存中的输入。输入既可以来自于支持 NITROS 的 Isaac ROS 节点,也可以来自于使用 NITROS 发布器的其他支持 CUDA 的 ROS 节点。与代管式 NITROS 发布器一样,这也能通过增加 GPU 和 CPU 之间的并行计算来提高性能。
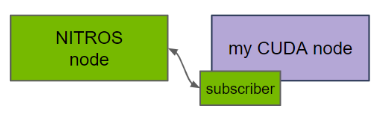
图 4. ROS 2 节点中的 NITROS 订阅器
为了更好地理解这一点,让我们来看一个基于 DNN 的点云分割示例图。总的来说,有三个主要的组件使用搭载 NITROS 的 CUDA:
代管式 NITROS 发布器和订阅器提供了一个可与标准的 rclcpp::Publisher 和 rclcpp::Subscriber API 相媲美的熟悉界面,使与现有 ROS 2 节点的集成更加直观。搭载 NITROS 的 CUDA 还能实现更加模块化的软件设计。借助代管式 NITROS 发布器和订阅器,CUDA 节点可以在图中的任何位置与 Isaac ROS 节点和其他 CUDA 节点一起使用,从而在每个节点上获得加速计算的优势。
再深入一点来看,NITROS 是基于 NVIDIA 图执行框架(GXF)开发的,它是一个用于构建高性能计算图的可扩展框架。NITROS 利用 GXF 实现了高效的 ROS 应用图。通过搭载 NITROS 的 CUDA,开发者无需了解使其节点支持 NITROS 的前提条件——GXF 的底层工作原理。GXF 层已被抽象化,用户只需进行简单的调整就能启用 NITROS,从而像往常一样轻松、快速地编写 ROS 2 节点。
访问网址进一步了解搭载 NITROS 的 CUDA 的核心概念:https://nvidia-isaac-ros.github.io/concepts/nitros/cuda_with_nitros.html#core-concepts
目前,代管式 NITROS 发布器和订阅器仅与 Isaac ROS NitrosTensorList 消息类型兼容。请访问 isaac_ros_nitros_type,查看完整的 NITROS 数据类型列表:https://github.com/NVIDIA-ISAAC-ROS/isaac_ros_nitros/tree/main/isaac_ros_nitros_type
使用搭载 NITROS 的 CUDA
和 YOLOv8 进行对象检测
Isaac ROS 提供了一个 YOLOv8 示例:https://github.com/NVIDIA-ISAAC-ROS/isaac_ros_object_detection/tree/main/isaac_ros_yolov8,展示了如何使用代管式 NITROS 实用程序和自定义 ROS 解码器来充分运用 NITROS。该示例使用来自 Isaac ROS DNN Inference 的软件包,通过 YOLOv8 来执行 TensorRT 加速的对象检测。代管式 NITROS 发布器和订阅器使用 NITROS 类型的消息,目前只与 Isaac ROS NitrosTensorList 消息类型兼容。这种消息类型用于在节点和 Isaac ROS DNN Inference 节点之间共享张量。

图 5. 使用 Isaac ROS DNN Inference 检测 YOLOv8 对象
假设您想使用由 Isaac ROS DNN Inference 和 CUDA NITROS 加速的自定义对象检测模型,检测流程涉及输入图像编码、DNN 推理以及输出解码三个主要步骤。Isaac ROS DNN Inference 实现了前两个步骤。
在解码步骤中,必须从推理结果(即张量)中提取相关信息。对于像 2D 物体检测这样的任务,相关信息包括边界框以及图像中每个检测到的输出的类别得分。
下面让我们来详细了解各个步骤。
第 1 步:编码
在输入方面,Isaac ROS 提供了一个由 NITROS 加速的 DNN 图像编码器。它会对输入图像进行预处理,并将其转换为张量,然后通过 isaac_ros_tensor_list 类型将张量传递给 TensorRT 或 Triton 节点进行推理。
您可以为各种预处理功能(如调整大小等)指定图像大小和网络期望的输入大小等参数。请注意,根据任务的不同,您需要使用不同的编码器。例如,由于网络期望的输入编码不同,您不能在语言模型中使用这种图像编码器。

图 6. Isaac ROS DNN 图像编码器节点概览
第 2 步:推理
Isaac ROS 为 DNN 推理提供两个 ROS 节点——TensorRT 节点和 Triton 节点。YOLOv8 样本目前使用其中的 TensorRT 节点。将训练好的模型提供给 TensorRT 节点,它就能执行推理并输出包含检测结果的张量。
输出的张量列表将传递给解码器节点。您可以指定网络所期望的维度和张量名称等参数,并且可以使用 Netron 等工具在 ONNX 模型中轻松找到这些信息。
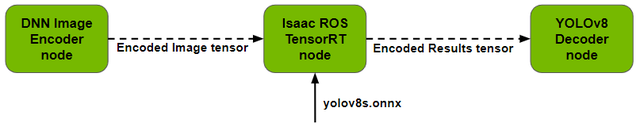
图 7. Isaac ROS TensorRT 推理节点概览
第 3 步:解码
从 TensorRT 或 Triton 节点推理出的输出张量必须解析为所需的边界框和类信息。比方说,您把模型的解码器写成了 ROS 2 节点(而且还不支持 NITROS)。
解码器节点并不支持 NITROS 类型的信息,而是期望从推理节点获得典型的 ROS 2 信息。由于 NITROS 保持了与非 NITROS 节点的兼容性,因此这种方法仍然有效。
不过在这种情况下,推理节点(位于 GPU 内存中)输出的 NITROS 类型消息会被转换成 ROS 2 消息,并被传送到 CPU 内存中供解码器使用。这将带来一些开销,因为数据现在位于 CPU 内存中,导致在与下游 ROS 节点协同工作时需要复制 CPU 内存。
现在,假设您想升级解码器,以便通过 NITROS 与推理节点(以及其他 NITROS 加速节点)进行通信,而不需要承担 CPU 内存复制的成本。在这种情况下,所有数据都会保留在 GPU 内存中。
在解码器节点中使用代管式 NITROS 订阅器就能轻松实现这一需求。该订阅器能够订阅来自推理节点的 NITROS 类型输出消息,并使用 NITROS 视图获取包含检测输出的 CUDA 缓冲区。然后,您就可以对这些数据执行解码逻辑,并通过适当的 ROS 消息类型发布结果。
YOLOv8 解码器可设置 NMS 阈值和置信阈值等参数以过滤候选检测结果。可使用一个简单的可视化节点订阅产生的 ROS 消息,并在输入图像上绘制边界框。请注意,代管式 NITROS 只能与 CPP ROS 2 节点集成。

图 8. YOLOv8 解码器节点概览
Isaac ROS NITROS 桥接器
如果您的机器人应用目前基于 ROS 1,仍可以使用新发布的 Isaac ROS NITROS 桥接器来获得加速计算的红利。这对使用 ROS 2 版本(Humble 之前的版本)的开发者来说也很有帮助,因为 ROS 2 版本不提供类型适配和协商功能。
NITROS 桥接器在 ROS 1 Noetic 和 NITROS 软件包之间传输 1080p 图像的速度比 ROS 1 桥接器快 2.5 倍,充分凸显了所实现的提速效果。
ROS 桥接器会产生基于 CPU 的内存复制成本,而 Isaac ROS NITROS 桥接器通过将数据从 CPU 转移到 GPU 消除了这一成本。这些数据可以在 GPU 内存中就地使用。
NITROS 桥接器由两个转换器节点组成。一个用于 ROS(例如 Noetic)一侧,另一个用于 ROS 2(例如 Humble)一侧。在不使用 NITROS 转换器的情况下,使用 ROS 桥接器会导致图像从 Noetic 发送到 Humble,然后再通过 CPU 内存中的 ROS 进程副本发送回来,从而增加延迟。这个问题在发送大量数据(如分割点云)的节点之间尤为明显。

图 9. 不使用 NITROS 转换器情况下的 ROS 桥接器
NITROS 桥接器的设计目标是减少跨 ROS 版本的端到端延迟。请看同一个例子,这次使用的是 NITROS 转换器。Noetic 一侧的转换器(图 10)将图像移至 GPU 内存,避免了通过桥接器复制 CPU 内存。Humble 侧的转换器(图 10)将 GPU 内存中的图像转换为 NITROS 图像类型,该类型与其他 NITROS 加速节点兼容。
反之亦然——图像数据作为 NITROS 图像通过两侧中任何一侧的转换器从 Humble 发送到位于 Noetic 的 CPU 可访问内存中的图像。
更多关于性能提升的信息,请访问 NITROS 桥接器:https://github.com/NVIDIA-ISAAC-ROS/isaac_ros_benchmark/blob/main/scripts/isaac_ros_nitros_bridge.py 和 ros1 桥接器的 Isaac ROS 基准:https://nvidia-isaac-ros.github.io/repositories_and_packages/isaac_ros_benchmark/index.html。请注意,Isaac ROS NITROS 桥接器尚不支持 NVIDIA Jetson 平台。

图 10. NITROS 桥接器概览
将 ROS 2 节点与 NITROS 集成的益处
下面总结了将 ROS 2 节点与 NITROS 集成的诸多益处:
尝试使用 Isaac ROS NITROS 和 YOLOv8 对象检测样本,加速您的 ROS 节点吧!
访问 NVIDIA Isaac ROS 文档页面了解有关我们硬件加速软件包的更多信息:https://nvidia-isaac-ros.github.io/index.html
您还可以登陆开发者论坛,了解更多有关 Isaac ROS 的最新信息:https://forums.developer.nvidia.com/c/agx-autonomous-machines/isaac/isaac-ros/600